

今回は、以下をやってみます。
- PyTorchでMLPを利用して、MNIST(手書き文字データ)を分類
- 転移学習が出来るように、モデルの学習結果をファイル保存
- ファイルから、モデルを復元する
この記事を書いた人

- エンジニア歴10数年
- SIerでDX推進を仕事に
- Python、AWSを使ったアーキテクチャ設計・アプリ開発が得意
- 30代、2児の父でサウナ好き
- [icon-class=”icon-twitter”]Twitter
また今回のプログラミングには、Pythonの知識が必要です。
Pythonを勉強する時、何から勉強するか分からず、挫折します。初心者でも、中級者でも、レベルに合わせた勉強方法を分かりやすくまとめています。

今回の開発環境
開発環境の前提は以下の通り。
- PyTorchを使用
- 開発環境は、Google Colaboratory
- テストデータは、MNIST(手書き文字データ)
コードの全体は、GitHubにアップロードしています。
MNIST(手書き文字データ)のデータ準備
まずは、必要なモジュールをインポートします。
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from torchvision import datasets, transforms
from torch.utils.data import DataLoaderそして今回はGoogle ColaboratoryのGPUを使いたいと思います。
ただし、Google ColaboratoryのGPUは使用制限があるため、GPUが使えないときはCPUを使うように、以下のコードを書きます。
device = "cuda" if torch.cuda.is_available() else "cpu"
device
# 以下は出力結果
cuda or cpuそしたら前処理をします。
MNISTデータをダウンロードして、画像を学習出来るようにTensorに変換します。
# 前処理
transform = transforms.Compose([
# 画像をTensorに変換してくれる
# チャネルラストをチャネルファーストに
# 0〜255の整数値を0.0〜1.0の浮動少数点に変換してくれる
transforms.ToTensor()
])
train_dataset = datasets.MNIST(root="./data", train=True, download=True, transform=transform)今回はデータ数が数万枚あるので、データを100個単位で学習させるために、ミニバッチに分けて学習していきます。
num_batches = 100
train_dataloader = DataLoader(train_dataset, batch_size=num_batches, shuffle=True)
train_iter = iter(train_dataloader)
# 100個だけミニバッチからデータをロードする
imgs, labels = train_iter.next()では、ミニバッチの中身を見てみます。
imgsのサイズはミニバッチ数の100個のデータ、チャンネルはグレースケールなので、1となってます。
また写真のサイズは28px * 28pxであることが分かります。
# 100個のデータ, グレースケール, 28px, 28px
imgs.size()
# 以下は出力値
torch.Size([100, 1, 28, 28])labelsの中身は手書き文字の正解値が入っています。
以下を見ると、先頭のデータは5であることが分かります。
labels
# 以下は出力値
tensor([5, 9, 4, 4, 3, 0, 4, 2, 6, 8, 1, 8, 0, 1, 0, 7, 9, 0, 6, 7, 4, 8, 4, 3,
6, 3, 2, 9, 0, 3, 8, 7, 9, 1, 0, 8, 6, 0, 2, 1, 0, 5, 6, 2, 7, 9, 3, 4,
5, 3, 0, 5, 7, 1, 0, 9, 7, 0, 9, 6, 7, 0, 1, 4, 9, 2, 7, 0, 9, 0, 2, 9,
5, 8, 5, 3, 1, 2, 5, 5, 0, 3, 5, 6, 3, 2, 9, 0, 7, 7, 4, 5, 9, 1, 6, 9,
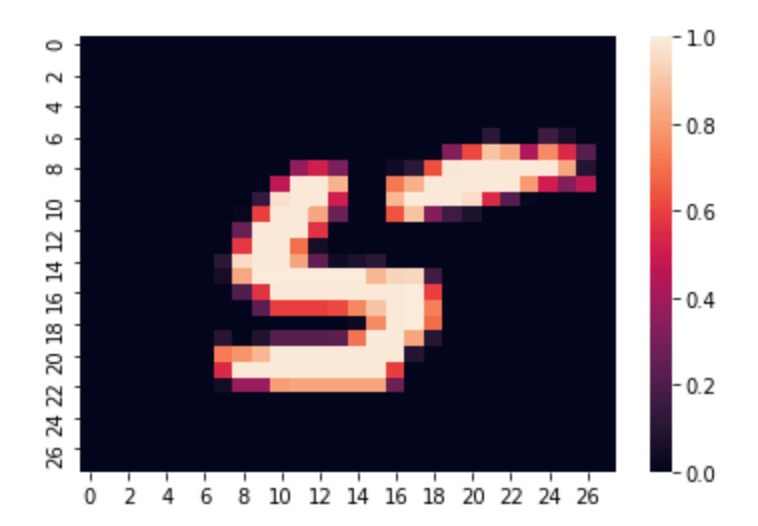
0, 9, 7, 8])では本当に先頭のデータは5なのか、写真を出力して見てみます。
img = imgs[0]
# 画像データを表示するために、チャネルファーストのデータをチャネルラストに変換する
img_permute = img.permute(1, 2, 0)
# tensorから2次元のarrayに変換する
sns.heatmap(img_permute.numpy()[:, :, 0])すると、以下のように写真も5であることが分かります。
MLPモデルの実装
では、MLPのモデルを実装していきます。
今回は活性化関数として、ReLU関数を使用します。
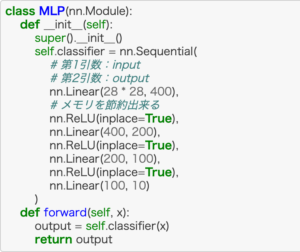
class MLP(nn.Module):
def __init__(self):
super().__init__()
self.classifier = nn.Sequential(
# 第1引数:input
# 第2引数:output
nn.Linear(28 * 28, 400),
# メモリを節約出来る
nn.ReLU(inplace=True),
nn.Linear(400, 200),
nn.ReLU(inplace=True),
nn.Linear(200, 100),
nn.ReLU(inplace=True),
nn.Linear(100, 10)
)
def forward(self, x):
output = self.classifier(x)
return outputそれでは、MLPの中身を見てみます。
先程定義したモデルの内容が出力されています。
model = MLP()
model.to(device)
# 以下は出力値
MLP(
(classifier): Sequential(
(0): Linear(in_features=784, out_features=400, bias=True)
(1): ReLU(inplace=True)
(2): Linear(in_features=400, out_features=200, bias=True)
(3): ReLU(inplace=True)
(4): Linear(in_features=200, out_features=100, bias=True)
(5): ReLU(inplace=True)
(6): Linear(in_features=100, out_features=10, bias=True)
)
)モデルの学習
では、ここからはモデルを学習させていきます。
損失関数についてはクロスエントロピーを使用して、最適化関数にはAdamを使用します。
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)では、ここまで準備が整ったので、実際に学習をするコードを書いていきます。
以下のようになります。
num_epochs = 15
losses = []
accs = []
for epoch in range(num_epochs):
running_loss = 0.0
running_acc = 0.0
for imgs, labels in train_dataloader:
imgs = imgs.view(num_batches, -1)
imgs = imgs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
output = model(imgs)
loss = criterion(output, labels)
running_loss += loss.item()
# dim=1 => 0-9の分類方向のMax値を返す
pred = torch.argmax(output, dim=1)
running_acc += torch.mean(pred.eq(labels).float())
loss.backward()
optimizer.step()
# 600回分で割る
running_loss /= len(train_dataloader)
running_acc /= len(train_dataloader)
losses.append(running_loss)
accs.append(running_acc)
print("epoch: {}, loss: {}, acc: {}".format(epoch, running_loss, running_acc))学習の結果が以下です。
epoch: 0, loss: 0.3144182890901963, acc: 0.9040172100067139
epoch: 1, loss: 0.10678012145062288, acc: 0.9672999978065491
epoch: 2, loss: 0.06977350709688229, acc: 0.978699266910553
epoch: 3, loss: 0.05080254869457955, acc: 0.9838324785232544
epoch: 4, loss: 0.03807236930190508, acc: 0.9884151220321655
epoch: 5, loss: 0.030108206117680916, acc: 0.9902483224868774
epoch: 6, loss: 0.02514307263501299, acc: 0.9920487403869629
epoch: 7, loss: 0.021965318746709574, acc: 0.99261474609375
epoch: 8, loss: 0.017465066731674597, acc: 0.9945650100708008
epoch: 9, loss: 0.01654982843004594, acc: 0.9944486618041992
epoch: 10, loss: 0.01726974661234029, acc: 0.9946150779724121
epoch: 11, loss: 0.012983597406328045, acc: 0.9957318902015686
epoch: 12, loss: 0.010266869831981846, acc: 0.9965323805809021
epoch: 13, loss: 0.014592967388795538, acc: 0.9951822757720947
epoch: 14, loss: 0.00960112084202592, acc: 0.9969321489334106最終的には99%近い性能が出るようになってきました。
では、損失の推移を見てみましょう。
plt.plot(losses)以下のように学習が進むにつれて、損失が小さくなっていくことが分かります。

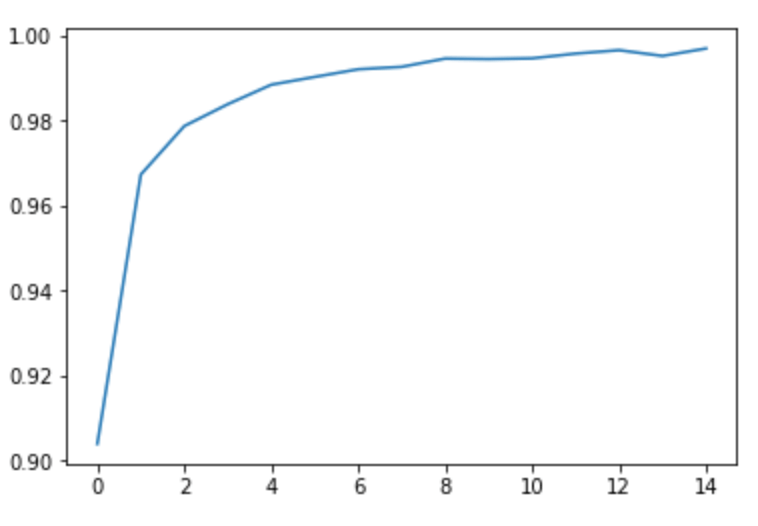
では、どれくらい正解出来るようになっているのかもグラフにして見てみます。
plt.plot(accs)いい感じで学習が出来ていることが分かりますね!
imgs_gpu = imgs.view(100, -1).to(device)
output= model(imgs_gpu)
pred = torch.argmax(output, dim=1)
pred
# こちらはモデルが予想した値
tensor([8, 4, 3, 2, 9, 7, 7, 6, 5, 8, 6, 4, 6, 5, 9, 6, 6, 7, 7, 6, 9, 3, 1, 7,
4, 0, 6, 8, 6, 7, 8, 9, 3, 6, 5, 9, 8, 6, 0, 4, 2, 1, 6, 8, 0, 8, 1, 0,
7, 8, 4, 2, 9, 3, 6, 1, 8, 1, 8, 4, 7, 2, 9, 0, 6, 8, 9, 9, 5, 7, 5, 8,
2, 5, 9, 0, 3, 7, 0, 7, 8, 5, 1, 1, 8, 4, 4, 0, 6, 3, 1, 0, 7, 4, 5, 0,
3, 0, 9, 8])
labels
# こちらは正解データ
tensor([8, 4, 3, 2, 9, 7, 7, 6, 5, 8, 6, 4, 6, 5, 9, 6, 6, 7, 7, 6, 9, 3, 1, 7,
4, 0, 6, 8, 6, 7, 8, 9, 3, 6, 5, 9, 8, 6, 0, 4, 2, 1, 6, 8, 0, 8, 1, 0,
7, 8, 4, 2, 9, 3, 6, 1, 8, 1, 8, 4, 7, 2, 9, 0, 6, 8, 9, 9, 5, 7, 5, 8,
2, 5, 9, 0, 3, 7, 0, 7, 8, 5, 1, 1, 8, 4, 4, 0, 6, 3, 1, 0, 7, 4, 5, 0,
3, 0, 9, 8])学習したモデルを保存する
では、ここまで学習させたモデルを保存します。モデルを保存しておくと、転移学習に使えます。
では、実際のコードです。
以下のようにして、学習済みの重みとバイアスを抜き出して、ファイルに出力します。
# 重み、バイアスを抜き出す
params = model.state_dict()
# 抜き出した重み、バイアスをprmファイルに保存する。
torch.save(params, "model.prm")以下のようにprmファイルが出来上がります。
!ls
# 以下は出力値
data model.prm sample_dataそして、保存した重み、バイアスを使って学習を再開したい時は、保存したファイルから重みとバイアスをパラメーターとして読み込み、モデルに渡します。
param_load = torch.load("model.prm")
model.load_state_dict(param_load)そして、また訓練用の処理をしたらいいだけです。
num_epochs = 10
losses = []
accs = []
for epoch in range(num_epochs):
running_loss = 0.0
running_acc = 0.0
for imgs, labels in train_dataloader:
imgs = imgs.view(num_batches, -1)
imgs = imgs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
output = model(imgs)
loss = criterion(output, labels)
running_loss += loss.item()
# dim=1 => 0-9の分類方向のMax値を返す
pred = torch.argmax(output, dim=1)
running_acc += torch.mean(pred.eq(labels).float())
loss.backward()
optimizer.step()
# 600回分で割る
running_loss /= len(train_dataloader)
running_acc /= len(train_dataloader)
losses.append(running_loss)
accs.append(running_acc)
print("epoch: {}, loss: {}, acc: {}".format(epoch, running_loss, running_acc))
すると、学習の初期の頃から高い精度が出ていることが分かると思います。
epoch: 0, loss: 0.01329927400600809, acc: 0.9961652755737305
epoch: 1, loss: 0.007679990973741345, acc: 0.9977990984916687
epoch: 2, loss: 0.008979191901667037, acc: 0.9971490502357483
epoch: 3, loss: 0.009341739794928496, acc: 0.9969989061355591
epoch: 4, loss: 0.007988007768026363, acc: 0.9976492524147034
epoch: 5, loss: 0.008332742984907781, acc: 0.9973315596580505
epoch: 6, loss: 0.006474268563735374, acc: 0.9979825615882874
epoch: 7, loss: 0.008563532610366261, acc: 0.9973323345184326
epoch: 8, loss: 0.005235775806599652, acc: 0.998366117477417
epoch: 9, loss: 0.008188722305379391, acc: 0.9978159666061401最後に
ここまでMLPを用いてMNISTを分類するモデルを作成しました。
 エソラ
エソラ意外と簡単に実装できるなと感じて頂けたと思います。
今後もDeep Learningの実装サンプルを記事にしますので、よろしくお願いします。
ここまでお読みいただき、ありがとうございました。
\ 更新の励みになるので、ポチッとしてね /
エソラ他にもスキルアップやキャリアアップの役に立つ情報が満載です。他の記事も読んで、ゆっくりしていってね!
この続きは以下から。
ディープラーニングの数学的な知識を身に着けたいなら、以下。
ディープ・ラーニングを本気で学ぶなら、Udemyがおすすめ
- 学習コンテンツ量が多いので、未経験から現場で活躍するレベルまで幅広い
- 疲れていても、動画で楽に学習出来る
- 疑問を気軽に聞けるQAシステムがあり、初心者でも安心
- セールが多数開催されるので、Udemy
 の料金は技術書よりも安い場合がある
の料金は技術書よりも安い場合がある - 30日以内なら、返金も可能
まとめると、「動画で楽に勉強が出来て、質問も出来て、しかも安い」という点が、Udemy
![]() の魅力です。
の魅力です。
エンジニアのスキルアップに終わりはありませんが、時代が進むにつれて、学習コストは低くなっています。技術書で独学するのに、限界を感じているのであれば、Udemy
![]() はぴったりです。
はぴったりです。
Udemyをもっと知りたいなら

もちろん、ディープ・ラーニングに関する講座も豊富です。どんな講座があるかは、以下から確認して下さい。
\ 動画だから、挫折しにくい /
※30日以内なら、返金あり
コメント