
今回は以下に挑戦します!
- CNNを使って、CIFAR10の画像データを分類
- 精度を上げるために、データ拡張で訓練データ数をかさ増し
この記事を書いた人

- エンジニア歴10数年
- SIerでDX推進を仕事に
- Python、AWSを使ったアーキテクチャ設計・アプリ開発が得意
- 30代、2児の父でサウナ好き
- [icon-class=”icon-twitter”]Twitter
また今回のプログラミングには、Pythonの知識が必要です。
Pythonを勉強する時、何から勉強するか分からず、挫折します。初心者でも、中級者でも、レベルに合わせた勉強方法を分かりやすくまとめています。

前提
開発環境の前提は以下の通り。
- PyTorchを使用
- 開発環境は、Google Colaboratory
- テストデータは、CIFAR-10
かなり重い処理になりますので、GPUを利用することをおすすめします。
Google ColaboratoryでもGPUを使えますが、無料枠の場合すぐになくなります。AWSのSageMakerを使ってGPUを利用する場合は、以下をご参照下さい。

テストデータはCIFAR10という画像データを使います。CIFAR-10とは、以下のdog(犬)やship(船)といった画像データを合計で10個集めて、正解ラベルをつけたデータセットです。
- plane(飛行機)
- car(車)
- bird(鳥)
- cat(猫)
- deer(鹿)
- dog(犬)
- frog(カエル)
- horse(馬)
- ship(船)
- truck(トラック)
MNIST(手書き文字データ)よりも、複雑なものが画像データとして写っているので、学習難易度は上がります。
コードの全体はGitHubにアップロードしています。
CIFAR10のデータ準備の実装サンプルコード
ライブラリのインポート、GPU使用
まずは必要なライブラリを、インポートします。
import torch
import torchvision
import torch.nn as nn
import torch.optim as optim
import numpy as np
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
from torch.utils.data import DataLoaderそしてGPUが使えたら使いたいので、「GPUが使えるのであればGPUを使うように、そうでなければCPUを使うように」という設定をします。
device = "cuda" if torch.cuda.is_available() else "cpu"データの変換
そして、以下のコードでデータを変換する処理をコーディングします。
val_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])transforms.ToTensor()はTensor型に変換をしています。
transforms.Normalize((0.5,), (0.5,))は第1引数が平均、第2引数が標準偏差を表し、それに合わせて正規化するように変換をします。
データ拡張
データ拡張とは、手元で使える画像データが少ない場合に、プログラムでデータを傾けたり、色彩を変化させて、データを擬似的に増やす手法です。
Deep Learningの分野ではデータ量は多ければ多いほど、良い精度が出る傾向にあるので、データ量を増やすことは非常に大切です。データ収集が難しい場合もあるので、是非覚えておきたい手法です。
やり方は簡単で、上記に実装したtransforms.Composeにコードを追加するだけです。
train_transform = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.ColorJitter(),
transforms.RandomRotation(10),
transforms.ToTensor(),
# チャネル毎に画像全体の平均値と標準偏差が0.5になるように標準化
transforms.Normalize((0.5,), (0.5,))
])上記のデータ拡張は以下のことをやっています。
| メソッド | 処理内容 |
|---|---|
| transforms.RandomHorizontalFlip() | ランダムに画像データを水平反転 |
| transforms.ColorJitter() | ランダムに画像の明るさ、コントラスト、彩度、色相を変える |
| transforms.RandomRotation() | ランダムに回転をさせる |
CIFAR10のダウンロード
そして、CIFAR10のデータを用意します。
CIFAR10のサンプルデータはPyTorchのライブラリを使って、インターネット経由でダウンロードしてきます。
今回は実際に訓練を行う訓練データと、検証用に使用するテストデータの2つに分けます。
train_dataset = datasets.CIFAR10(root="./data", train=True, download=True, transform=train_transform)
test_dataset = datasets.CIFAR10(root="./data", train=False, download=True, transform=val_transform)そして、以下のようにデータローダーにそれぞれのデータを代入します。
# 訓練用データ
train_dataloader = DataLoader(train_dataset, batch_size=32, shuffle=True)
# テスト用データ
test_dataloader = DataLoader(test_dataset, batch_size=32, shuffle=False)データの中身を見てみます。
data_iter = iter(train_dataloader)
imgs, labels = data_iter.next()ラベルを出すると、以下のように数値の正解ラベルが入っています。
labels
# 以下は出力値
tensor([5, 9, 8, 4, 3, 4, 4, 7, 2, 6, 8, 0, 6, 0, 7, 2, 3, 6, 4, 8, 0, 7, 8, 6,
5, 3, 8, 5, 9, 0, 4, 1])では、写真を出力してみます。
img = imgs[0]
img_permute = img.permute(1, 2, 0)
img_permute = 0.5 * img_permute + 0.5
img_permute = np.clip(img_permute, 0, 1)
plt.imshow(img_permute)鹿の画像が出ました!

CNNモデルの実装サンプルコード
では、ここからCNNのモデル実装をしていきます。
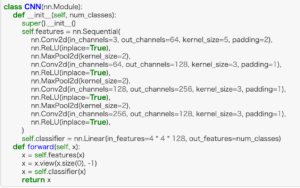
モデルの全体像は以下のようになります。
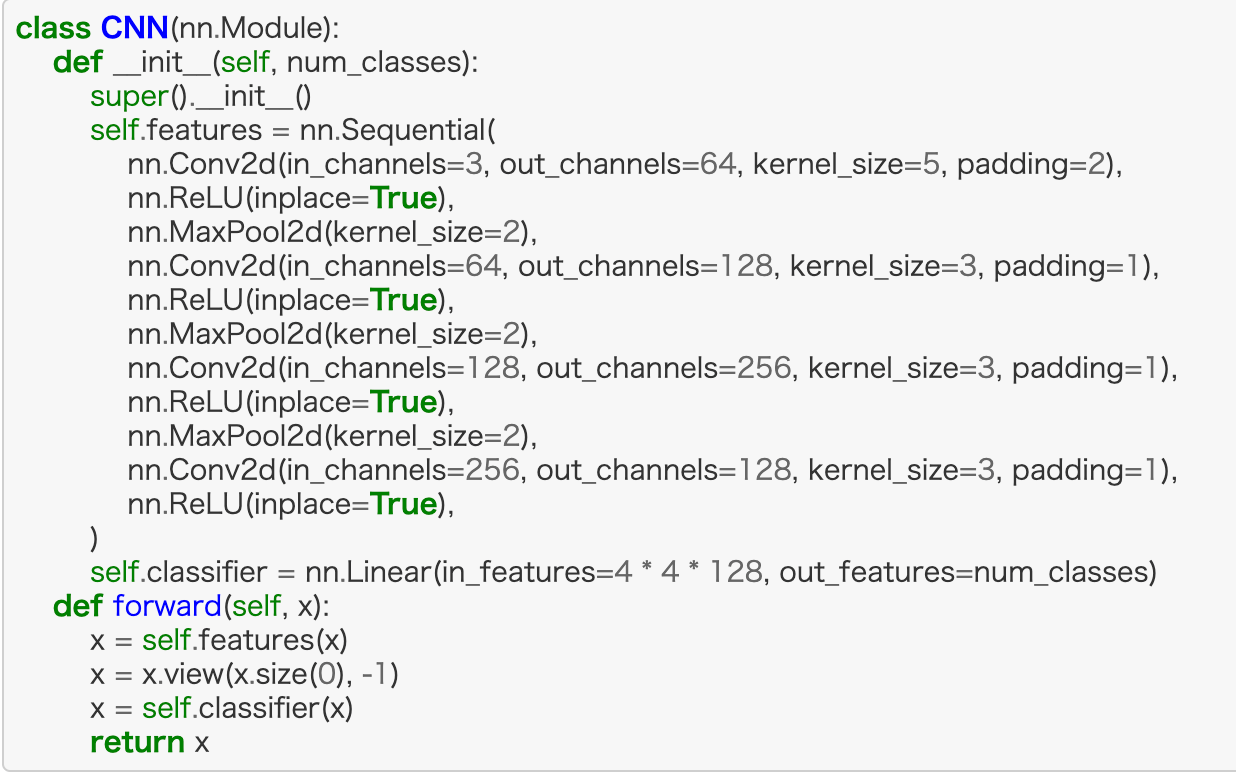
class CNN(nn.Module):
def __init__(self, num_classes):
super().__init__()
self.features = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=64, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(in_channels=256, out_channels=128, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
)
self.classifier = nn.Linear(in_features=4 * 4 * 128, out_features=num_classes)
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return xポイントは以下。
- nn.Conv2dで畳み込みフィルターを使用
- 活性化関数にはReLUを使用
- nn.MaxPool2dでマックスプーリング
model = CNN(10)
model.to(device)損失関数はクロスエントロピーを選択し、最適化関数はAdamを使用します。
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001, weight_decay=5e-4)CNNモデルの訓練処理の実装サンプルコード
それでは、学習をさせます。
最初に訓練データでモデルを学習させて、テストデータで検証をします。
num_epochs = 15
losses = []
accs = []
val_losses = []
val_accs = []
for epoch in range(num_epochs):
running_loss = 0.0
running_acc = 0.0
for imgs, labels in train_dataloader:
imgs = imgs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
output = model(imgs)
loss = criterion(output, labels)
loss.backward()
running_loss += loss.item()
pred = torch.argmax(output, dim=1)
running_acc += torch.mean(pred.eq(labels).float())
optimizer.step()
running_loss /= len(train_dataloader)
running_acc /= len(train_dataloader)
losses.append(running_loss)
accs.append(running_acc)
#
# test loop
#
val_running_loss = 0.0
val_running_acc = 0.0
for val_imgs, val_labels in test_dataloader:
val_imgs = val_imgs.to(device)
val_labels = val_labels.to(device)
val_output = model(val_imgs)
val_loss = criterion(val_output, val_labels)
val_running_loss += val_loss.item()
val_pred = torch.argmax(val_output, dim=1)
val_running_acc += torch.mean(val_pred.eq(val_labels).float())
val_running_loss /= len(test_dataloader)
val_running_acc /= len(test_dataloader)
val_losses.append(val_running_loss)
val_accs.append(val_running_acc)
print("epoch: {}, loss: {}, acc: {}, \
val loss: {}, val acc: {}".format(epoch, running_loss, running_acc, val_running_loss, val_running_acc))すると、以下のような結果になります。
epoch: 0, loss: 1.433305179813468, acc: 0.47696736454963684, val loss: 1.0972439880950002, val acc: 0.6093250513076782
epoch: 1, loss: 1.0305320225460592, acc: 0.6342170238494873, val loss: 0.9065422707091505, val acc: 0.682707667350769
epoch: 2, loss: 0.8761650123469584, acc: 0.6921985149383545, val loss: 0.8051631742011244, val acc: 0.7189496755599976
epoch: 3, loss: 0.7819633651870379, acc: 0.7235084772109985, val loss: 0.7636748775125692, val acc: 0.7327276468276978
epoch: 4, loss: 0.7313383280353827, acc: 0.7460412979125977, val loss: 0.7061512276006583, val acc: 0.7598841786384583
epoch: 5, loss: 0.6902052811034124, acc: 0.7585172653198242, val loss: 0.710792664140939, val acc: 0.7541933059692383
epoch: 6, loss: 0.6601356580824861, acc: 0.7694937586784363, val loss: 0.6813203324905981, val acc: 0.769069492816925
epoch: 7, loss: 0.6379130195709505, acc: 0.7775911688804626, val loss: 0.653992762390417, val acc: 0.776457667350769
epoch: 8, loss: 0.6179025139533322, acc: 0.7821897268295288, val loss: 0.6546257712399236, val acc: 0.7769568562507629
epoch: 9, loss: 0.5969862834868032, acc: 0.7906469702720642, val loss: 0.6211730434586065, val acc: 0.7905351519584656
epoch: 10, loss: 0.5893858630288814, acc: 0.7949455976486206, val loss: 0.634566101212852, val acc: 0.780451238155365
epoch: 11, loss: 0.5731508998118069, acc: 0.8000239729881287, val loss: 0.6467042784816541, val acc: 0.7775558829307556
epoch: 12, loss: 0.5638545042264942, acc: 0.8032429814338684, val loss: 0.6207450504024951, val acc: 0.7892372012138367
epoch: 13, loss: 0.5516865827758115, acc: 0.8065218925476074, val loss: 0.6165681539442592, val acc: 0.7894368767738342
epoch: 14, loss: 0.5429838309666322, acc: 0.8096808791160583, val loss: 0.6213038140973344, val acc: 0.7946285605430603損失関数の学習経過をグラフにしてみます。
plt.style.use("ggplot")
plt.plot(losses, label="train loss")
plt.plot(val_losses, label="test loss")
plt.legend()以下のように、徐々に損失が小さくなっていることが分かります。
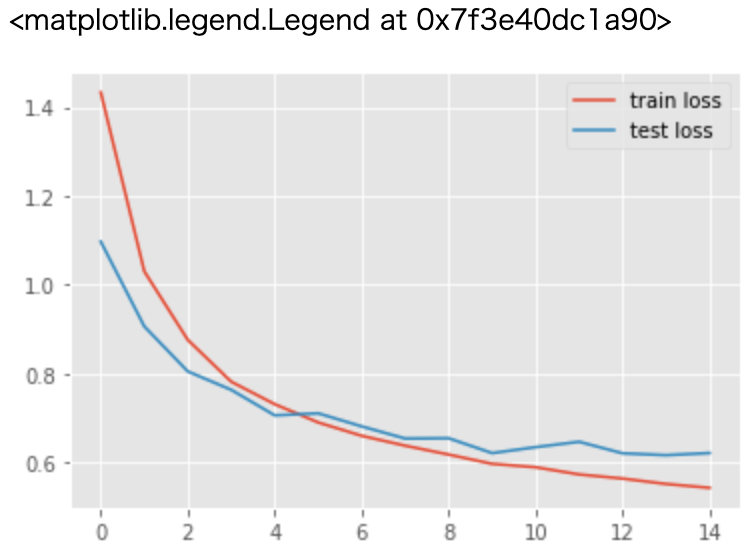
次は正解率をグラフにして見てみます。
plt.plot(accs, label="train acc")
plt.plot(val_accs, label="test acc")
plt.legend()こちらも徐々に正解率が上がっていくことが分かります。
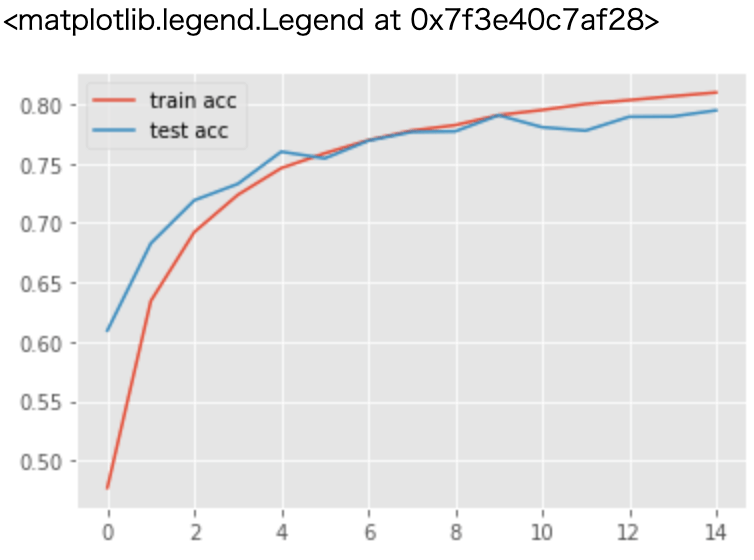
最後に
ここまでで「CNNでデータ拡張をしながら、CIFAR10を分類する」サンプルコードを実装しました、
PyTorchであれば結構簡単に実装が出来ることを感じられたと思います。
この続きは以下から。

ディープラーニングの数学的な知識を身に着けたいなら、以下。

ここまでお読みいただき、ありがとうございました。
\ 更新の励みになるので、ポチッとしてね /
 エソラ
エソラ他にもスキルアップやキャリアアップの役に立つ情報が満載です。他の記事も読んで、ゆっくりしていってね!
ディープ・ラーニングを本気で学ぶなら、Udemyがおすすめ
- 学習コンテンツ量が多いので、未経験から現場で活躍するレベルまで幅広い
- 疲れていても、動画で楽に学習出来る
- 疑問を気軽に聞けるQAシステムがあり、初心者でも安心
- セールが多数開催されるので、Udemy
 の料金は技術書よりも安い場合がある
の料金は技術書よりも安い場合がある - 30日以内なら、返金も可能
まとめると、「動画で楽に勉強が出来て、質問も出来て、しかも安い」という点が、Udemy
![]() の魅力です。
の魅力です。
エンジニアのスキルアップに終わりはありませんが、時代が進むにつれて、学習コストは低くなっています。技術書で独学するのに、限界を感じているのであれば、Udemy
![]() はぴったりです。
はぴったりです。
Udemyをもっと知りたいなら

もちろん、ディープ・ラーニングに関する講座も豊富です。どんな講座があるかは、以下から確認して下さい。
\ 動画だから、挫折しにくい /
※30日以内なら、返金あり
コメント